Quick Start Guide
This tutorial will walk you through your first video translation task from start to finish.
Core Features at a Glance
- Full Automatic Video & Audio Translation: Intelligently transcribes speech from audio/video, generates source-language subtitle files, translates them to the target language, creates dubbing, and finally merges the new audio and subtitles into the original video — all in one go (left panel: Translate A/V).
- Speech To Text: Batch-transcribes speech from video or audio files into SRT subtitle files with precise timecodes (left panel: Transcribe Translate).
- Text-to-Speech (TTS): Generates high-quality, natural-sounding dubbing for your text or SRT subtitle files using a variety of advanced TTS providers (left panel: Batch Dubbing).
- Batch SRT Translate: Batch-translates SRT subtitle files while preserving original timecodes and formatting, with multiple bilingual subtitle styles available (left panel: Batch SRT Translate).
How It Works
The core functionality of pyVideoTrans is video translation — automatically translating a video from one language to another:
[Original Video] --> [Speech Recognition] --> [Subtitle Translation] -->
[TTS] --> [Audio-Visual Sync] --> [Translated Video Output]In plain terms:
- Speech Recognition: Like a transcriptionist, it writes down exactly what people say in the video as subtitles
- Subtitle Translation: Translates the transcribed subtitles into the target language
- TTS: Uses AI voice to "read" the translated subtitles, generating dubbing audio
- Sync & Alignment: Re-aligns the new dubbing with the original video to ensure audio and visuals stay in sync
The entire process is fully automatic — just select your files, configure settings, and click Start.
Download & Installation
Windows Users
- Download the pre-built package: Download Windows Version
- Extract to a short path containing only English letters and numbers (e.g.
D:\pyVideoTrans) - Double-click
sp.exeto launch
⚠️ Do not run directly from inside the archive. If GPU acceleration is needed, make sure CUDA 12.8 and cuDNN 9 are installed
Click for notes to avoid most errors
- Do not extract to system folders like
C:/Program FilesorC:/Windowsthat require special permissions, since the software writes generated and temporary files to the extraction path. - It is recommended to extract the software into a folder containing only English letters and numbers, such as
D:/videotrans, then extract the archive into this folder. Including any Chinese characters, spaces, or special symbols in the path is strongly discouraged, and the path should not be too deep. - Keep video filenames short — under 30 characters works well, while hundreds of characters is too long. Combined with the full path and other command arguments, this may exceed the Windows system limit and cause errors.
Filenames should not contain special characters like ":?*, as these can also cause errors on Windows. Videos downloaded from YouTube often have extremely long filenames with various special characters — using them without modification will very likely cause issues on Windows. It is recommended to rename them to short, clean names.
- On Windows, enable file extension display (hidden by default) to avoid errors, especially when entering reference audio paths.
Open any folder, click Navigation Bar > View > File name extensions to enable it. Once enabled, mp4 videos will show the .mp4 extension, and wav audio will show .wav.
macOS / Linux Users
Install dependencies:
bash# macOS brew install ffmpeg libsndfile git # Ubuntu/Debian sudo apt-get install ffmpeg libsndfile1-devInstall uv:
bashcurl -LsSf https://astral.sh/uv/install.sh | shClone and launch:
bashgit clone https://github.com/jianchang512/pyvideotrans.git cd pyvideotrans uv sync uv run sp.py
Interface Overview
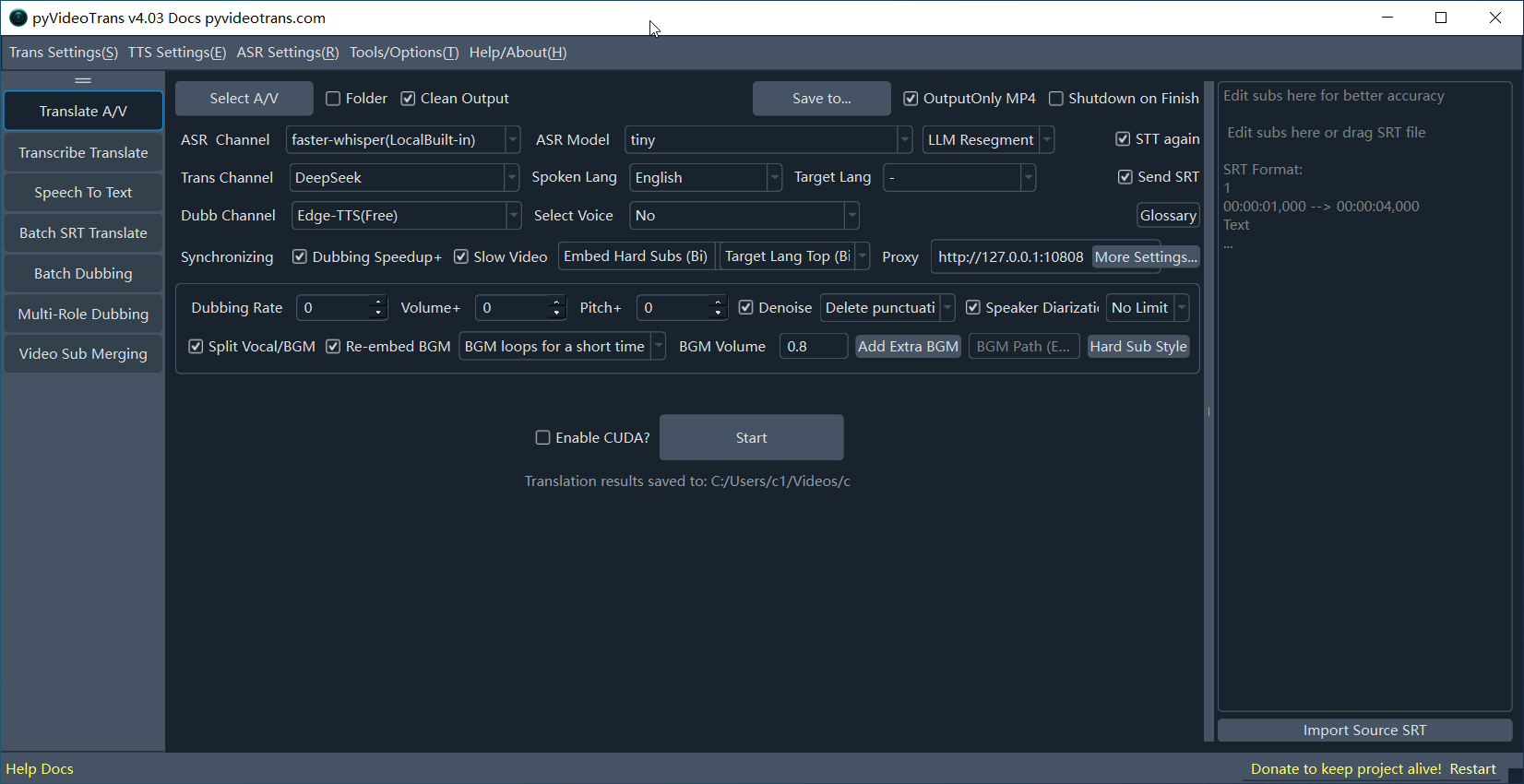
After launching the software, the main interface is divided into the following rows from top to bottom:
| Row | Content | Description |
|---|---|---|
| Row 1 | Select A/V | Supports mp4/mkv/avi/mov/wav/mp3 and other formats |
| Row 2 | ASR Channel | Select recognition provider and model for converting speech to subtitles |
| Row 3 | Trans Channel | Select translation provider, source language, and target language for translating subtitles from the previous step |
| Row 4 | Dubb Channel | Select dubbing provider and voice actor to dub the translated subtitles |
| Row 5 | Sync & Alignment | Dubbing speedup, slow video, speech rate/volume, subtitle embedding |
| Row 6 | Start | Click to begin processing |
| Row 7 | Progress bar | Shows processing progress; click to open the output folder |
| Row 8 | More Settings | Advanced options including denoising and background sound processing |
What do "Free", "Local API", and "Local Built-in" mean?
- Free: Examples include Google Translate, Microsoft Translator, and Edge-TTS. These providers are free to use online with no configuration needed — just be aware of rate-limiting errors that may occur with heavy usage.
- Local API: Many open-source models can be deployed locally on your own machine. After deployment, enter the API address or WebUI address in the pyVideoTrans settings interface, and the software will call your deployed model service. Examples include GPT-SoVITS / CosyVoice / F5-TTS, etc.
- Local Built-in: Some models can be conveniently integrated directly into pyVideoTrans without separate deployment, ready to use out of the box — for example VITS / Piper / Qwen3-TTS / Qwen3-ASR / SuperionTTS / ChatterBox, etc. Note that to avoid unlimited software size growth, only the calling code is built in; the models themselves are not included and must be downloaded online on first use. Subsequent launches may also check for model updates, so an internet connection is required. For fully offline use, you would need to deploy from source and modify the code with AI assistance.
Model download sources:
huggingface.co/hf-mirror.com(China mirror) /modelscope.cn(Alibaba ModelScope) /github.com
Your First Translation: Step-by-Step
Using the example of translating a Chinese video into English.
Step 1: Select Video File
Click the Select A/V button to choose the file you want to translate. Supports mp4/mkv/avi/mov/wav/mp3 and other formats.
Folder: Check this option to batch-process all videos in a folder.Clean Output: If you need to reprocess the same video (rather than using cached results), check this option. Otherwise, cached files from the previous run will be used.Save to...: By default, translated files are saved to a_video_outfolder in the original video's directory. Click this button to set a custom output directory.OutputOnly MP4: When selected, only the final translated video is kept in the output; all other subtitle and audio files are automatically deleted.Shutdown on Finish: Automatically shuts down the computer after all tasks are complete — useful for large batches or long-running tasks.
Step 2: Select ASR Channel
| Provider | Recommended For | Description |
|---|---|---|
faster-whisper (Local Built-in) | Default recommendation | Fast and high quality |
openai-whisper (Local Built-in) | High accuracy needs | Slightly more accurate, slower |
Qwen-ASR (Local Built-in) | Chinese video | Excellent Chinese recognition |
Model selection:
tiny→ Fastest, low accuracybase/small→ Balanced choicemedium→ Good qualitylarge-v3→ Best quality, requires 8GB+ VRAMlarge-v3-turbo→ Recommended, best balance of speed and quality
Second Pass Recognition and Default Segmentation / LLM Resegment
- Second Pass Recognition: When dubbing is selected and "Embed Hard Subs" is enabled, you can enable second pass recognition. After dubbing is complete, the software will perform speech recognition on the dubbed audio to generate shorter subtitles that are precisely aligned with the dubbing. (Configure the maximum and minimum speech duration in Advanced Options > ASR Settings — shorter values produce smaller subtitle segments.)
- Default Segmentation vs. LLM Resegment: "LLM Resegment" sends the recognized text to an LLM to fix typos and re-segment long passages for more fluent results. Configure which translation provider to use for LLM resegmentation under
Tools/Options(T) > More Settings... > LLM Resegment. Note that LLM resegmentation may sometimes produce worse results, since quality depends on the model's intelligence. When usingclonevoice (dubbing role set toclone), it is recommended to stick with default segmentation instead.
The LLM resegmentation prompt is located at
<software directory>/videotrans/prompts/recharge/recharge-llm.txt— you can customize it.If both Second Pass Recognition and LLM Resegment are enabled, the software will apply LLM resegmentation again after the second pass. That prompt is at
<software directory>/videotrans/prompts/recharge/recharge-llm.txt2.
Step 3: Select Translation Channel
| Provider | Description |
|---|---|
Google (Free) | Good translation quality; requires proxy for users in China |
Microsoft (Free) | No proxy needed; may be rate-limited |
M2M100 (Local) | Local model translation |
| DeepSeek | Excellent AI translation quality; affordable and recommended |
Then select Spoken Lang (the language spoken in the video) and Target Lang (the language you want to translate into).
Step 4: Select Dubbing Channel
| Provider | Description |
|---|---|
Edge-TTS (Free) | Default recommendation; Microsoft's free interface with natural-sounding voices |
Qwen3-TTS (Local Built-in) | Alibaba's local model; good quality, slower |
ChatterBox (Local Built-in) | Multi-language, high quality |
After selecting a provider, the Select Voice dropdown will update with the available voices. Selecting clone means the dubbing will use the voice timbre from the original video.
Step 5: Adjust Sync & Subtitle Settings
| Parameter | Default | Description |
|---|---|---|
| Dubbing Speedup+ | ✅ Enabled | Speeds up dubbing when it is longer than the original video |
| Slow Video | ☐ Disabled | Slows down the video when dubbing is longer than the original |
| Subtitle type | Embed Hard Subs | Permanently burns subtitles into the video |
Subtitle types:
- No subtitles: Replaces audio only, no subtitles added
- Embed Hard Subs: Subtitles permanently burned into the video; visible in any player
- Embed Soft Subs: Subtitles as a separate track; togglable in the player
- Embed Hard Subs (Bilingual): Shows both original and translated text simultaneously
- Embed Soft Subs (Bilingual): Bilingual subtitle track; togglable in the player
Learn about the dubbing, subtitle, and video sync alignment mechanism
Step 6: Start
Enable CUDA?: If you have an NVIDIA GPU with CUDA 12.8 and cuDNN 9 installed, check this option for several times faster speech recognition.
Click the 🚀 Start button. The progress bar at the bottom displays real-time progress. Click the progress bar to open the output folder. When complete, the translated video is automatically saved to the output folder.
More Settings

Click More Settings... to expand:
| Parameter | Description |
|---|---|
| Denoise | Removes background noise from audio |
| Split Vocal/BGM | Separates vocals from background music |
| Re-embed BGM | Re-embeds background audio after separation |
| Background volume | Adjusts background volume (0.0–2.0) |
| Delete punctuati... / Restore punctuation | Controls punctuation in subtitles |
| Dubbing Rate | Adjusts dubbing speed (−50% to +50%) |
| Volume+ | Adjusts dubbing volume (−95% to +100%) |
| Pitch+ | Adjusts dubbing pitch (−100Hz to +100Hz) |
Lossless Video Output
To preserve the original video quality in the output, ensure all of the following conditions are met:
- The original video is encoded as H.264 (libx264) in MP4 format
- Slow Video is unchecked
- Subtitle type is set to No subtitles or Embed Soft Subs
- In Advanced Options, the 264/265 encoder is set to
264
Full Advanced Options Reference
Access via Tools/Options(T) > More Settings...:
General Settings
| Parameter | Description | Default |
|---|---|---|
| UI Language | Requires restart after change | zh |
| Single Video Interactive Pause Countdown | Seconds to pause for editing | 30 |
| Batch Output Directory | Output location for batch operations | output/ |
| Retry Count on Failure | Retries for recoverable errors | 1 |
| CPU Concurrent Tasks | Maximum CPU concurrency | Auto |
| GPU Concurrent Tasks | GPU concurrency | 1 |
Video Output Control
| Parameter | Description | Default |
|---|---|---|
| Video Output Quality (CRF) | 0=lossless, 51=lowest quality | 23 |
| Output Video Preset | ultrafast → veryslow | medium |
| 264/265 Encoder | 264 for compatibility, 265 for compression | 264 |
| Output Video Format | mp4 or mkv | mp4 |
ASR Parameters
| Parameter | Description | Default |
|---|---|---|
| Voice Threshold | VAD voice probability threshold | 0.5 |
| Max Speech Duration (seconds) | Forces split beyond this duration | 6 |
| Min Speech Duration (milliseconds) | Merges shorter segments with neighbors | 3000 |
| Silence Split (milliseconds) | Splits at silence longer than this | 140 |
| beam_size | Recognition accuracy 1–5 | 5 |
Subtitle Translation Settings
| Parameter | Description | Default |
|---|---|---|
| Traditional Translation Batch Size | Lines per request for traditional providers | 5 |
| AI Translation Batch Size | Lines per request for AI providers | 20 |
| Send Full Subtitles | Includes timecodes with AI translation | Yes |
Dubbing Settings
| Parameter | Description | Default |
|---|---|---|
| Concurrent Dubbing Threads | Simultaneous dubbing threads | 1 |
| EdgeTTS Concurrency | Higher = faster, but may hit rate limits | 10 |
Subtitle-Audio-Video Alignment
| Parameter | Description | Default |
|---|---|---|
| Max Audio Speedup | Maximum acceleration factor | 100 |
| Max Video Slowdown | Maximum slowdown factor | 10 |
| CJK Subtitle Max Characters/Line | Triggers line wrap beyond this | 15 |
FAQ
Q: Processing is very slow?
- Make sure GPU acceleration (CUDA) is enabled
- Use a smaller model
- Ensure your GPU drivers are up to date
Q: Recognition results are inaccurate?
- Check that Spoken Lang is correctly selected
- Try switching to a larger model
- Enable the Denoise feature
- Adjust the Voice Threshold parameter
Q: After translation, audio, subtitles, and video are out of sync?
This is normal. Different languages have different syllable counts and grammar structures, so dubbing duration inevitably changes. Solutions:
- Enable Dubbing Speedup+ (enabled by default)
- Also enable Slow Video if needed
- Adjust Dubbing Rate to speed up the overall pace
Q: The output video file is too large?
- Increase the Video Output Quality (CRF) value (e.g. 25–30)
- Switch the encoder from 264 to 265
- Disable Slow Video
Q: How to use GPU acceleration?
Make sure NVIDIA GPU drivers, CUDA 12.8, and cuDNN 9.11 are installed, then check Enable CUDA? on the main interface. AMD GPUs do not support CUDA acceleration.
Q: Conditions for lossless video output?
Original video must be H.264 MP4 + Slow Video unchecked + no embedded hard subtitles + encoder set to 264.
Related Documentation
- Improve AI Translation Quality — Translation mode comparison and glossary usage
- Using Local LLMs as Translation Providers — Local LLM configuration guide
- Customize AI Translation Prompts — Customize translation prompts
- Best Results Recommendations — Optimal configuration for each stage
- Blank Subtitle Lines After Translation — Causes and solutions