TTS Channel: F5-TTS / Spark-TTS / Index-TTS / Dia-TTS / VoxCPM / Confucius-TTS
From v3.68 onwards, these TTS services share a single settings interface. Simply enter the WebUI address of the running TTS service (default is usually
http://127.0.0.1:7860), then select the corresponding service from the "TTS Channel" dropdown on the main screen.
This document covers deployment and integration for 6 open-source TTS services. They all expose an API through a Gradio WebUI, so configuration is essentially the same across all of them.
Overview
| Service | Developer | Supported Languages | Default Address | Project |
|---|---|---|---|---|
| F5-TTS | Shanghai Jiao Tong University | Chinese, English (extensible) | http://127.0.0.1:7860 | https://github.com/SWivid/F5-TTS |
| Spark-TTS | SparkAudio | Chinese, English | http://127.0.0.1:7860 | https://github.com/SparkAudio/Spark-TTS |
| Index-TTS | Bilibili (open-source) | Chinese, English | http://127.0.0.1:7860 | https://github.com/index-tts/index-tts |
| Dia-TTS | nari-labs | English only | http://127.0.0.1:7860 | https://github.com/nari-labs/dia |
| VoxCPM-TTS | ModelBest (open-source) | 30+ languages | http://127.0.0.1:7860 | https://github.com/OpenBMB/VoxCPM |
| Confucius-TTS | NetEase Youdao | 14 languages | http://127.0.0.1:7860 | https://github.com/netease-youdao/Confucius4-TTS |
The integration flow is identical for all services: start the WebUI → enter the address in pyVideoTrans → select the channel → configure reference audio → use.
Prerequisites
Before using these TTS services, make sure you have:
- pyVideoTrans version: v3.68 or higher
- Hardware: An NVIDIA GPU is recommended for acceleration; some services also run on CPU (much slower)
- Network: The first launch may download models from HuggingFace
- Python environment: Python 3.9+ and Git are needed if deploying from source
F5-TTS
What is F5-TTS
F5-TTS is an open-source TTS service developed by Shanghai Jiao Tong University. It supports Chinese and English voice synthesis and voice cloning.
Deployment
Option A: Windows Package (recommended for beginners)
- Baidu Cloud download: https://pan.baidu.com/s/1A6jBECIQ41OZaa8yTDCgjA?pwd=1234
- HuggingFace download: https://huggingface.co/mortimerme/repocollect/resolve/main/f5-tts0528.7z?download=true
Download, extract, and double-click the startup script.
Option B: From Source
Follow the official project documentation: https://github.com/SWivid/F5-TTS
Starting the WebUI
After starting, the default address is http://127.0.0.1:7860. Open this in your browser to test voice synthesis.
Configuring in pyVideoTrans
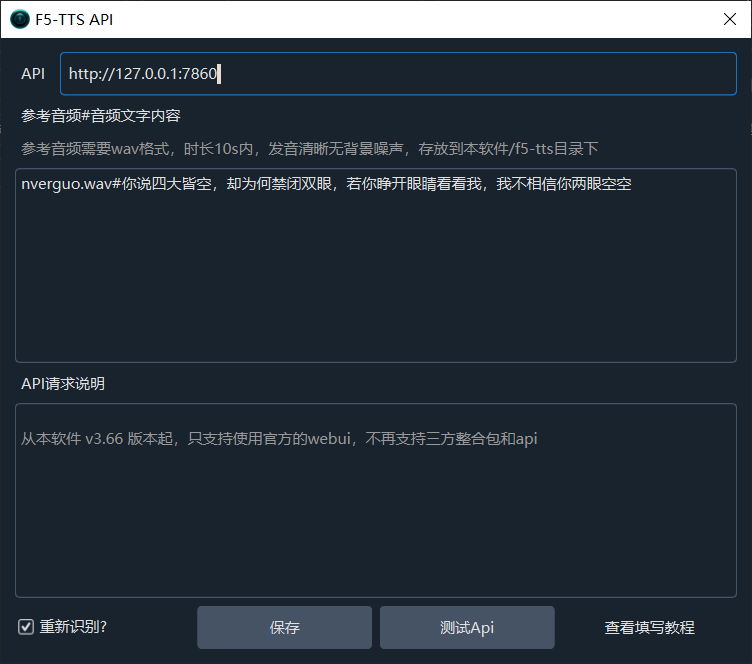
- Open the software, go to Menu → TTS Settings → F5-TTS/Spark-TTS/index-TTS/Dia-TTS
- Enter the WebUI address:
http://127.0.0.1:7860 - Click "Test" — if no errors appear, configuration is successful
- Select "F5-TTS" from the "TTS Channel" dropdown on the main screen
Index-TTS
What is Index-TTS
Index-TTS is an open-source TTS service from Bilibili that supports Chinese and English voice cloning with excellent audio quality.
Deployment
Windows Package
- Baidu Cloud download: https://pan.baidu.com/s/1dmLdhJgBC7HlfY-hITMVeg?pwd=1234
- HuggingFace download: https://huggingface.co/mortimerme/repocollect/resolve/main/indextts2-0529.7z?download=true
From Source
Follow the official documentation: https://github.com/index-tts/index-tts
Starting the WebUI
After starting, the default address is http://127.0.0.1:7860. Configuration is identical to F5-TTS.
Note: Only the official Index-TTS WebUI is supported. If you're using a third-party package, replace its
webui.pywith the one from the official source code, otherwise it may not work.
VoxCPM-TTS
What is VoxCPM-TTS
VoxCPM-TTS is an open-source TTS service from ModelBest that supports 30+ languages, including various Chinese dialects.
Supported Languages
- International (30+): Arabic, Burmese, Chinese, Danish, Dutch, English, Finnish, French, German, Greek, Hebrew, Hindi, Indonesian, Italian, Japanese, Khmer, Korean, Lao, Malay, Norwegian, Polish, Portuguese, Russian, Spanish, Swahili, Swedish, Tagalog, Thai, Turkish, Vietnamese
- Chinese Dialects: Mandarin, Sichuanese, Cantonese, Wu, Northeastern, Henan, Shaanxi, Shandong, Tianjin, Minnan
Deployment
Deploy from source following the official documentation: https://github.com/OpenBMB/VoxCPM
After starting the WebUI, the default address is http://127.0.0.1:7860. Configuration is identical to F5-TTS.
Spark-TTS
What is Spark-TTS
Spark-TTS is an open-source TTS service from SparkAudio that supports Chinese and English voice cloning.
Deployment
Deploy from source following the official documentation: https://github.com/SparkAudio/Spark-TTS
After starting the WebUI, the default address is http://127.0.0.1:7860. Configuration is identical to F5-TTS.
Dia-TTS
What is Dia-TTS
Dia-TTS is an open-source TTS service from nari-labs. English only.
Deployment
Deploy from source following the official documentation: https://github.com/nari-labs/dia.git
After starting the WebUI, the default address is http://127.0.0.1:7860. Configuration is identical to F5-TTS.
Confucius-TTS
What is Confucius-TTS
Confucius-TTS is an open-source TTS service from NetEase Youdao that supports 14 languages.
Supported Languages
Chinese, English, Japanese, Korean, German, French, Spanish, Indonesian, Italian, Thai, Portuguese, Russian, Malay, Vietnamese
Deployment
Windows Package
- Baidu Cloud download: https://pan.baidu.com/s/1rtrlJ5pE7wAm4bbpl72x3A?pwd=1234
- HuggingFace download: https://huggingface.co/mortimerme/repocollect/resolve/main/confucius4-2026-0624.7z?download=true
The package can be used directly by double-clicking 启动webui.bat (Start WebUI).
From Source (extra steps required)
The official source code does not include a WebUI or API, so it cannot be directly integrated. After deploying from source:
- Download webui.py
- Place
webui.pyin the official source directory - Install the gradio module:
pip install gradio - Start with:
python webui.py
After starting, the default address is http://127.0.0.1:7860. Configuration is identical to F5-TTS.
Configuring Reference Audio
Reference audio is configured globally under Menu → TTS Settings → Set Reference Audio.
Steps
- Open the "Reference Audio" settings panel
- Enter the following format in the "Reference Audio" text box:
audio_filename#text corresponding to the audio- Place the reference audio files in the
f5-ttsfolder under the pyVideoTrans project root directory (create the folder manually if it doesn't exist)
Example
Suppose you have an audio file nverguo.wav containing the speech "Queen of Women speaking", you would enter:
nverguo.wav#Queen of Women speaking
Reference Audio Requirements
| Item | Requirement |
|---|---|
| Format | WAV (recommended); MP3 and other formats also work |
| Duration | 3–12 seconds (F5-TTS max is 12s; longer audio is auto-truncated) |
| Content | Clear pronunciation, no background noise |
| Text | Must match the audio content exactly |
Adding Other Languages to F5-TTS
By default, F5-TTS uses the official Chinese and English models. To use other languages, modify the src/f5_tts/infer/infer_gradio.py file in the F5-TTS project directory.
How to Modify
Find the code around line 59:
DEFAULT_TTS_MODEL_CFG = [
"hf://SWivid/F5-TTS/F5TTS_v1_Base/model_1250000.safetensors",
"hf://SWivid/F5-TTS/F5TTS_v1_Base/vocab.txt",
json.dumps(dict(dim=1024, depth=22, heads=16, ff_mult=2, text_dim=512, conv_layers=4)),
]Code location diagram:

Replace the code above with the model configuration for the desired language (see below), then restart F5-TTS.
Important: After making changes, the program will download new language models online. Test once through the WebUI first to confirm everything works before using pyVideoTrans. Also make sure the text language in pyVideoTrans matches the model language selected in F5-TTS.
Language Model Configurations
French:
DEFAULT_TTS_MODEL_CFG = [
"hf://RASPIAUDIO/F5-French-MixedSpeakers-reduced/model_last_reduced.pt",
"hf://RASPIAUDIO/F5-French-MixedSpeakers-reduced/vocab.txt",
json.dumps({"dim": 1024, "depth": 22, "heads": 16, "ff_mult": 2, "text_dim": 512, "text_mask_padding": False, "conv_layers": 4, "pe_attn_head": 1}),
]Hindi:
DEFAULT_TTS_MODEL_CFG = [
"hf://SPRINGLab/F5-Hindi-24KHz/model_2500000.safetensors",
"hf://SPRINGLab/F5-Hindi-24KHz/vocab.txt",
json.dumps({"dim": 768, "depth": 18, "heads": 12, "ff_mult": 2, "text_dim": 512, "text_mask_padding": False, "conv_layers": 4, "pe_attn_head": 1})
]Italian:
DEFAULT_TTS_MODEL_CFG = [
"hf://alien79/F5-TTS-italian/model_159600.safetensors",
"hf://alien79/F5-TTS-italian/vocab.txt",
json.dumps({"dim": 1024, "depth": 22, "heads": 16, "ff_mult": 2, "text_dim": 512, "text_mask_padding": False, "conv_layers": 4, "pe_attn_head": 1})
]Japanese:
DEFAULT_TTS_MODEL_CFG = [
"hf://Jmica/F5TTS/JA_25498980/model_25498980.pt",
"hf://Jmica/F5TTS/JA_25498980/vocab_updated.txt",
json.dumps({"dim": 1024, "depth": 22, "heads": 16, "ff_mult": 2, "text_dim": 512, "text_mask_padding": False, "conv_layers": 4, "pe_attn_head": 1})
]Russian:
DEFAULT_TTS_MODEL_CFG = [
"hf://hotstone228/F5-TTS-Russian/model_last.safetensors",
"hf://hotstone228/F5-TTS-Russian/vocab.txt",
json.dumps({"dim": 1024, "depth": 22, "heads": 16, "ff_mult": 2, "text_dim": 512, "text_mask_padding": False, "conv_layers": 4, "pe_attn_head": 1})
]Spanish:
DEFAULT_TTS_MODEL_CFG = [
"hf://jpgallegoar/F5-Spanish/model_last.safetensors",
"hf://jpgallegoar/F5-Spanish/vocab.txt",
json.dumps({"dim": 1024, "depth": 22, "heads": 16, "ff_mult": 2, "text_dim": 512, "conv_layers": 4})
]Finnish:
DEFAULT_TTS_MODEL_CFG = [
"hf://AsmoKoskinen/F5-TTS_Finnish_Model/model_common_voice_fi_vox_populi_fi_20241206.safetensors",
"hf://AsmoKoskinen/F5-TTS_Finnish_Model/vocab.txt",
json.dumps({"dim": 1024, "depth": 22, "heads": 16, "ff_mult": 2, "text_dim": 512, "text_mask_padding": False, "conv_layers": 4, "pe_attn_head": 1})
]Check the official updates for additional languages, which can be added in a similar way. See: https://github.com/SWivid/F5-TTS/blob/main/src/f5_tts/infer/SHARED.md
Common Errors and Troubleshooting
1. Don't Close the Terminal Window
While the API is in use, you can close the WebUI in your browser, but you must not close the terminal window that started the TTS service.
2. Cannot Switch Models Dynamically
You cannot dynamically switch models in F5-TTS. You need to manually edit the code and restart the WebUI.
3. HuggingFace Connection Timeout
If you see an error like:
requests.exceptions.ConnectTimeout: HTTPSConnectionPool(host='huggingface.co', port=443): Max retries exceededThis is a network connectivity issue. Ensure you can reach huggingface.co.
4. API Endpoint Reference
| Service | Gradio API Endpoint |
|---|---|
| F5-TTS | /basic_tts |
| Spark-TTS | /voice_clone |
| Index-TTS | /gen_single |
| Dia-TTS | /generate_audio |
| VoxCPM-TTS | /generate |
| Confucius-TTS | /_clone_fn |
These endpoints are called automatically by the software — no manual configuration needed.
5. Reference Audio Duration Limits
- F5-TTS: max 12 seconds; longer audio is auto-truncated
- Other services: 3–10 seconds recommended
6. Version Compatibility
- Ensure pyVideoTrans version ≥ v3.68
- Each TTS service must use the official WebUI (third-party packages may have API incompatibilities)