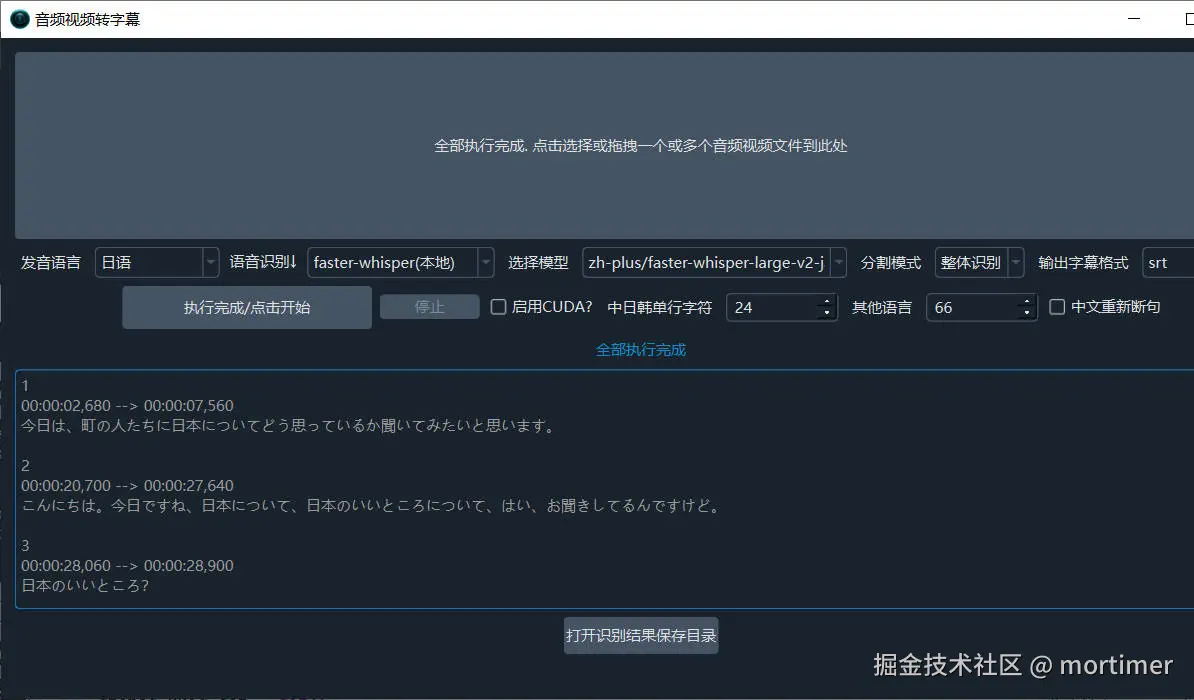
Video translation software typically includes various speech recognition channels to transcribe human speech in audio and video into subtitle files. For English and Chinese, these software tools perform reasonably well. However, their effectiveness is often unsatisfactory when dealing with low-resource languages such as Japanese, Korean, and Indonesian.
This is because the training data for large language models from abroad is predominantly in English, and their performance in Chinese is also less than ideal. Similarly, the training data for domestic models is largely concentrated on Chinese and English, with Chinese occupying a higher proportion.
The lack of training data leads to poor model performance. Fortunately, the Hugging Face website https://huggingface.co hosts a vast number of fine-tuned models, including many specifically fine-tuned for low-resource languages, which perform quite well.
This article explains how to use Hugging Face models in video translation software for recognizing low-resource languages, using Japanese as an example.
1. Accessing the Internet
Due to network restrictions, the https://huggingface.co website is not directly accessible from within the country. You need to configure your network environment yourself to ensure you can access the site.
After accessing it, you will see the homepage of the Hugging Face website.
2. Navigate to the Models Directory
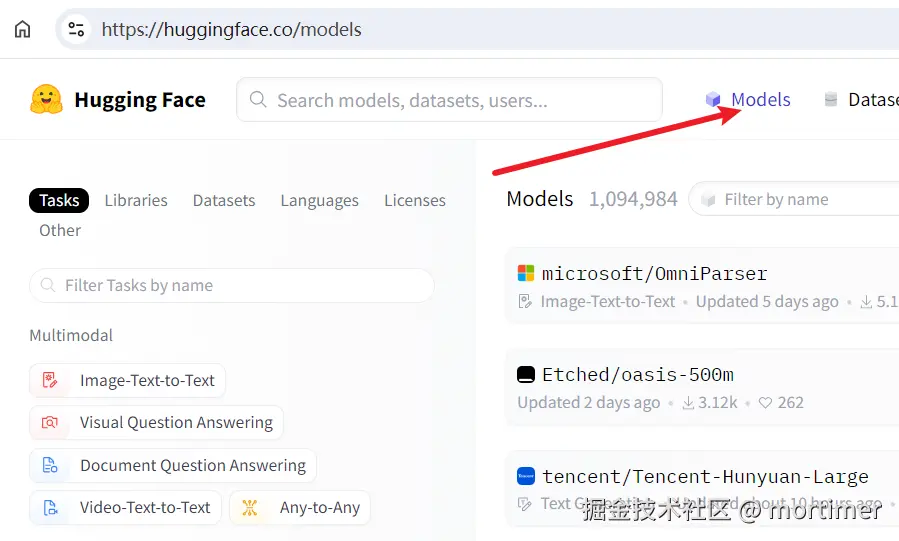
Click on the "Automatic Speech Recognition" category in the left navigation bar. The right side will display all speech recognition models.
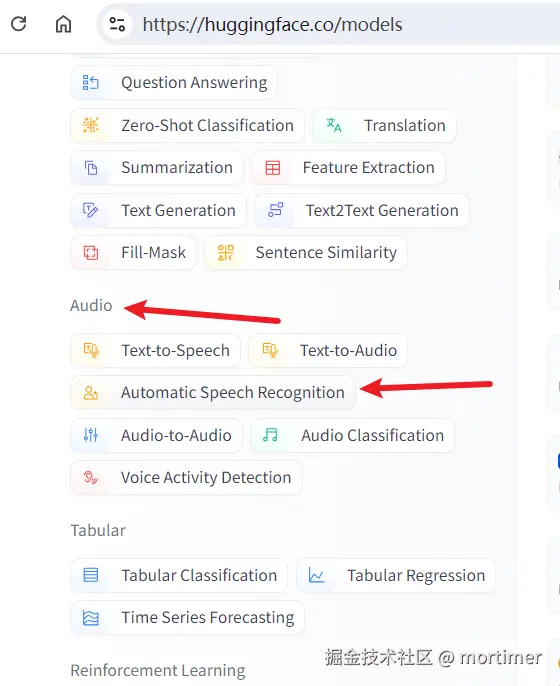
3. Find Models Compatible with faster-whisper
The Hugging Face website currently hosts 20,384 speech recognition models, but not all of them are suitable for video translation software. Different models return data in different formats, and video translation software is only compatible with models of the faster-whisper type.
- Search for "faster-whisper" in the search box.
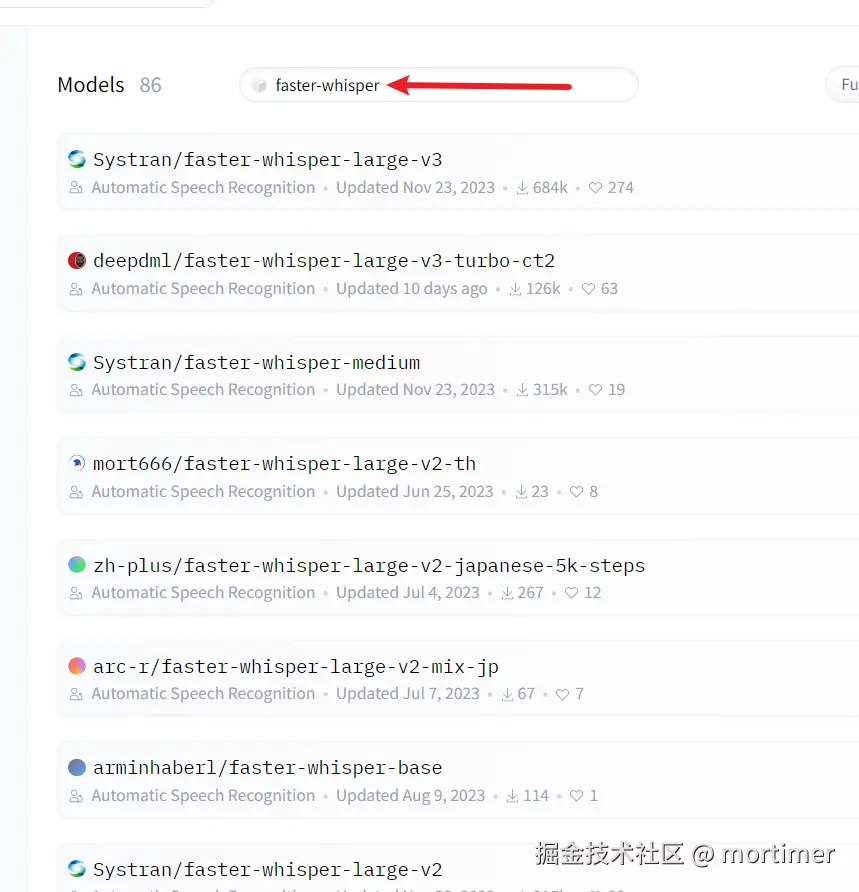
The search results are mostly models that can be used in video translation software.
Of course, some models are compatible with faster-whisper but do not contain "faster-whisper" in their names. How can you find these models?
- Search for the language name, such as "japanese," then click into the model details page to see if the model description states compatibility with faster-whisper.
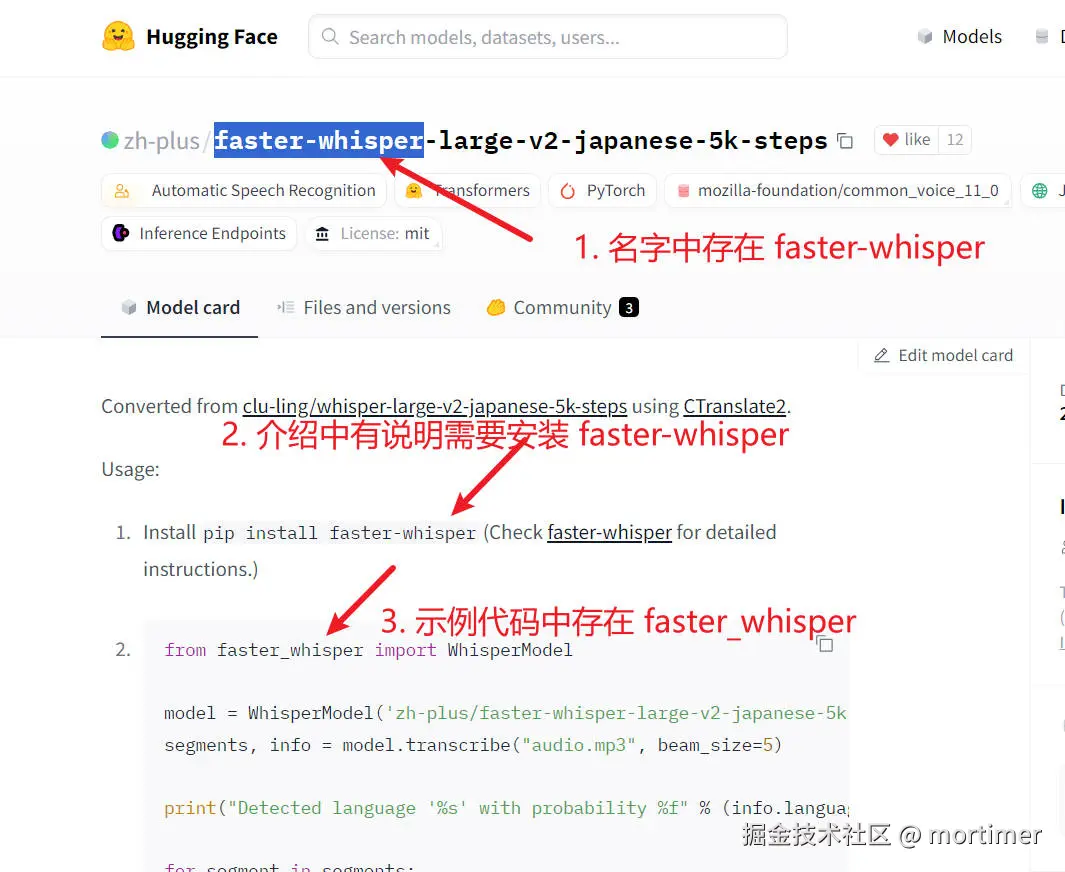
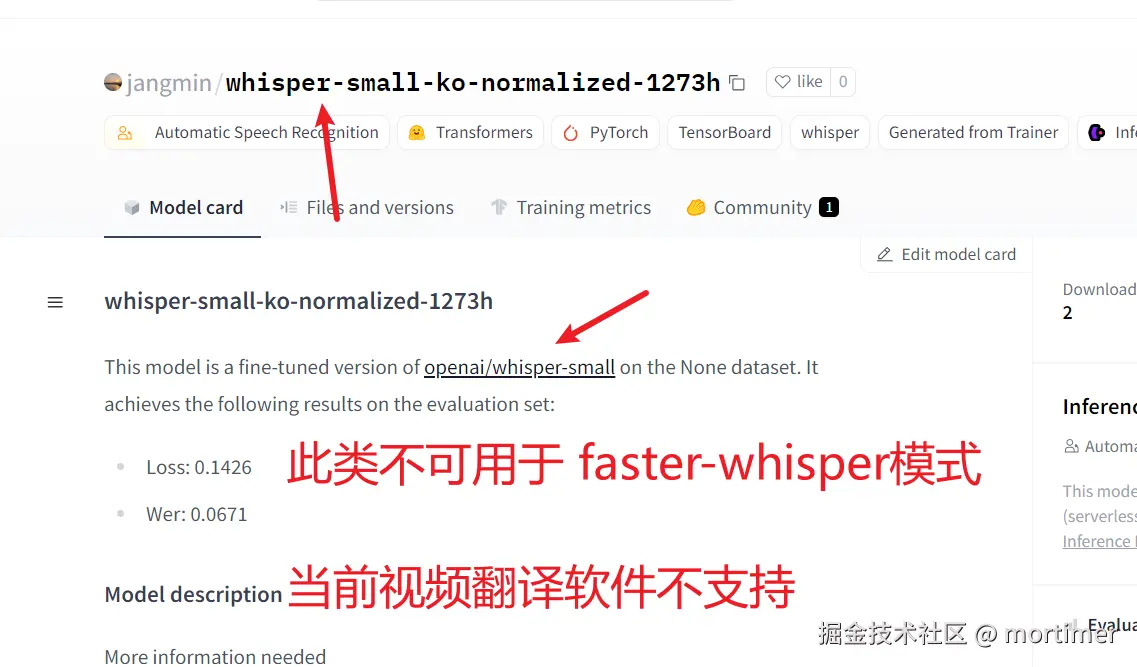
If the model name or description does not explicitly mention faster-whisper, the model is not usable. Even if terms like "whisper" or "whisper-large" appear, they are not usable because "whisper" is for compatibility with the openai-whisper mode, which is not currently supported by video translation software. Whether it will be supported in the future depends on the circumstances.
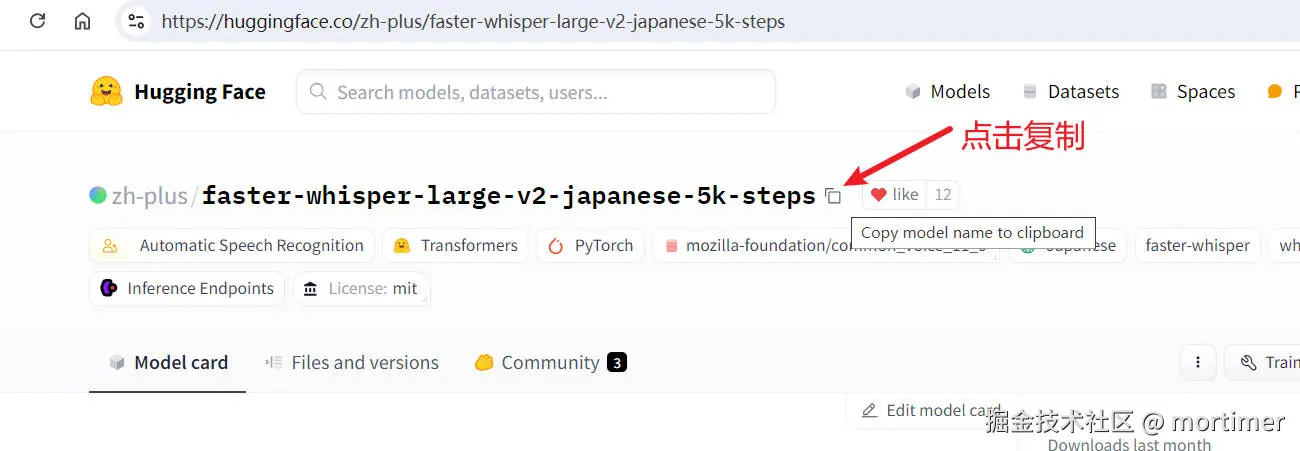
4. Copy the Model ID to the Video Translation Software
Once you find a suitable model, copy the model ID and paste it into the video translation software under "Menu" -> "Tools" -> "Advanced Options" -> "faster and openai model list".
Copy the model ID.
Paste it into the video translation software.
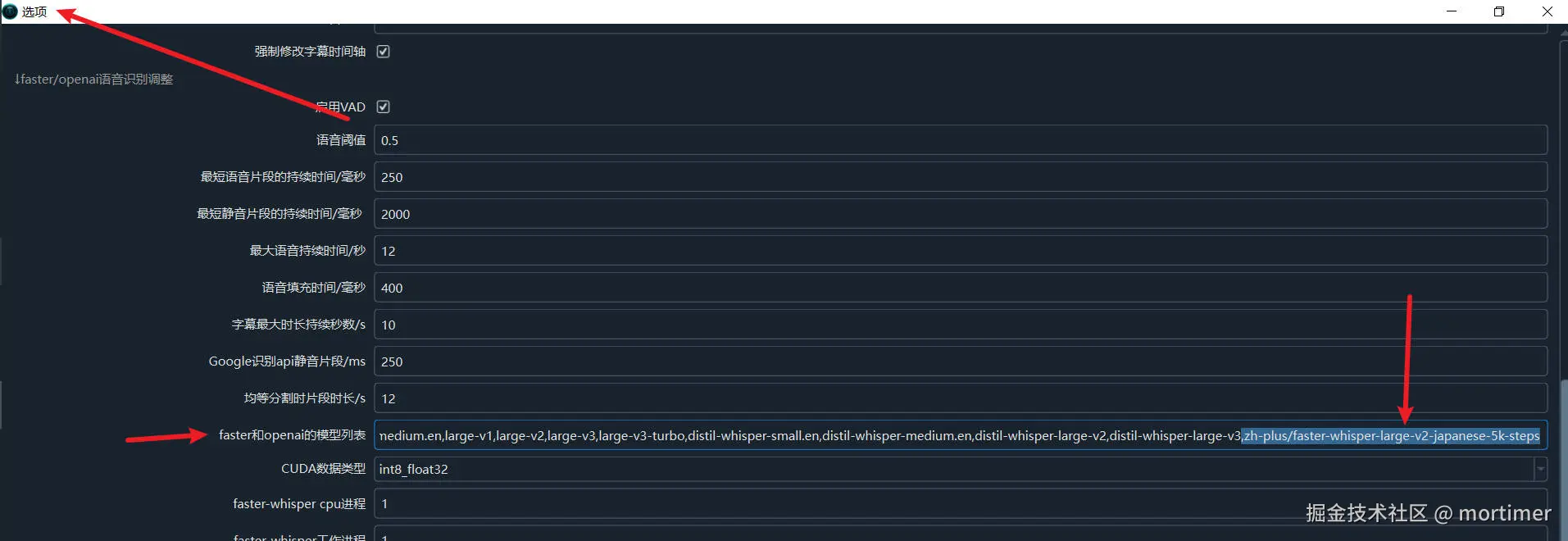
Save the settings.
5. Select the faster-whisper Mode
In the speech recognition channel, select the model you just added. If it doesn't appear, restart the software.
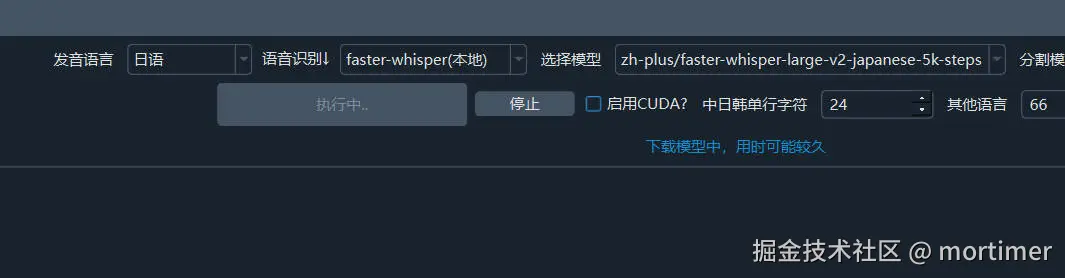
After selecting the model and the source language, you can start recognition.
Note: You must set up a proxy; otherwise, you cannot connect and will receive an error. You can try setting up a global computer proxy or a system proxy. If you still get an error, enter the proxy IP and port into the "Network Proxy" text box on the main interface.
For an explanation of network proxy, please visit https://pyvideotrans.com/proxy
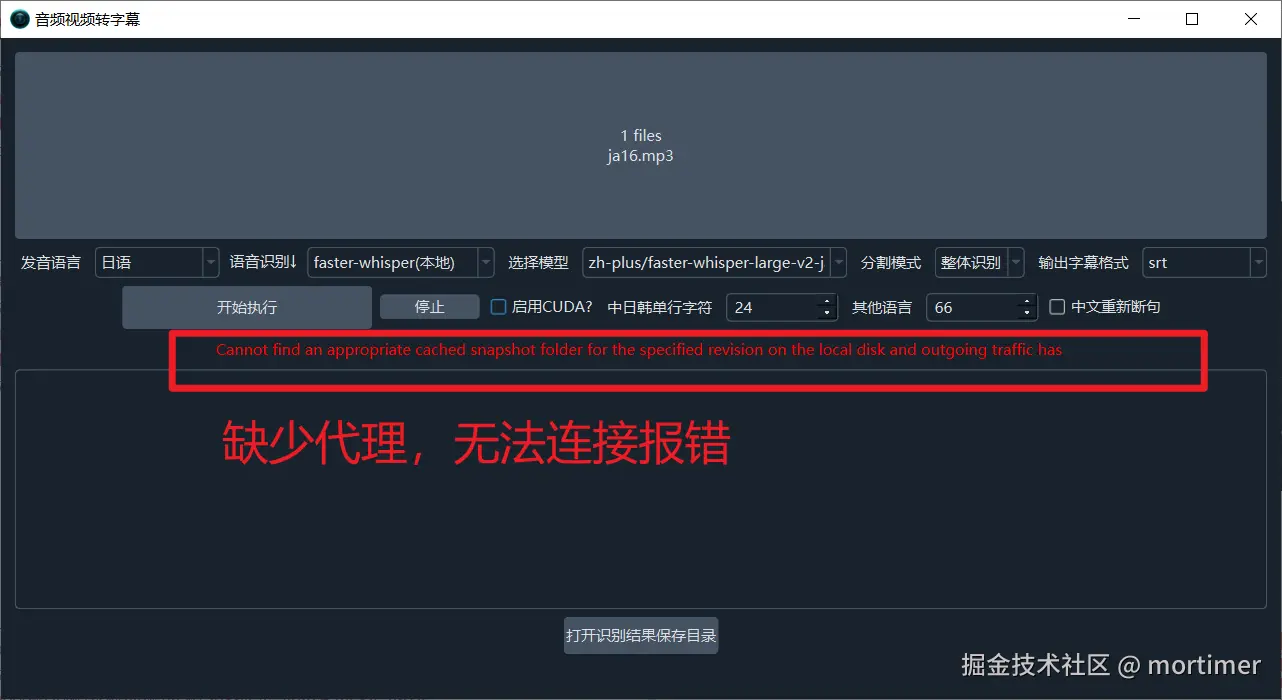
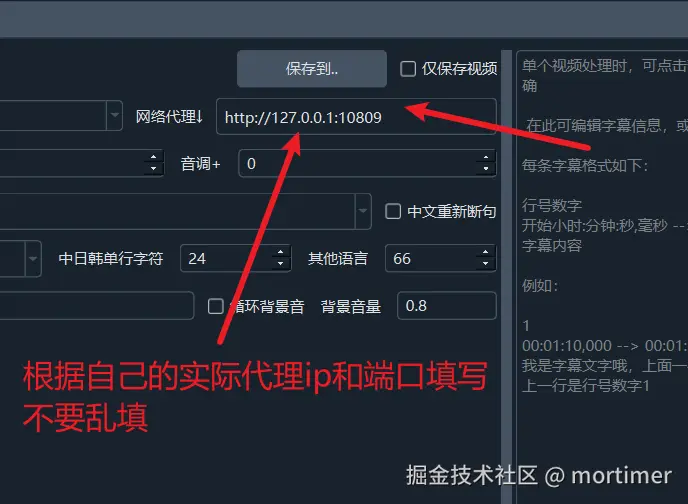
Depending on your network conditions, the download process may take a long time. As long as no red error message appears, please be patient.