VAD Parameter Tuning for Speech Recognition
During the speech recognition phase of video translation, generated subtitles may sometimes be too long (tens of seconds or even minutes) or too short (less than 1 second). Adjusting VAD (Voice Activity Detection) parameters can help fix these issues and make subtitles better match the actual speech content.
What is VAD?
VAD (Voice Activity Detection) is a tool that identifies speech segments in audio, separating speech from silence or noise. When combined with speech recognition tools like Whisper, VAD can detect and split speech segments before and after recognition, improving overall accuracy.
The current version uses silero as the default VAD model. You can switch to ten-vad in Menu > Tools/Options(T) > More Settings....
Parameter Details and Tuning Tips
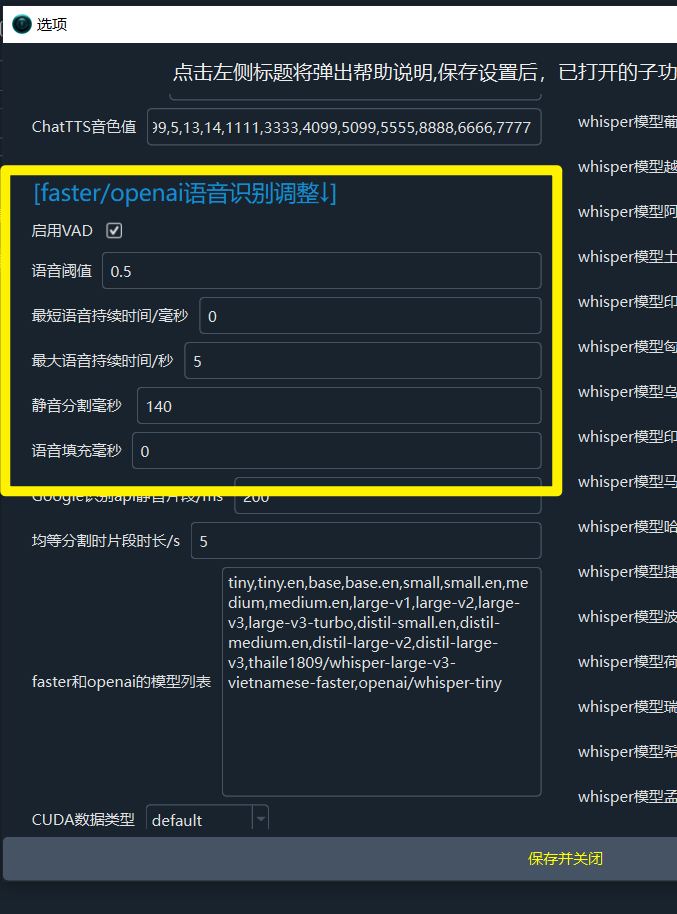
Core Parameters
| Parameter | Description | Default | Tuning Tip |
|---|---|---|---|
| Select VAD | Choose which VAD model to use | silero | Generally keep the default |
| Speech Threshold | Minimum probability for an audio segment to be considered speech; lower = more sensitive | 0.5 | Lower values increase sensitivity but may misclassify noise as speech |
| Max Speech Duration (s) | Force-split segments exceeding this length | 5 | Set to 3-4 for shorter subtitles; 8-10 for longer ones |
| Min Speech Duration (ms) | Segments shorter than this try to merge with adjacent subtitles | 2000 | Set to 1000-1500 for shorter subtitles |
| Merge Short Subtitles | Must be checked to enable merging of short subtitles | No | Generally recommended to enable |
| Silence Split Duration (ms) | Only split at silences longer than this value | 140 | Increase to reduce the number of splits |
| Non-speech Threshold | Decrease to reduce hallucinations, but may miss some words | -- | Generally keep the default |
Advanced Parameters
| Parameter | Description | Default |
|---|---|---|
| Sampling Temperature | Controls randomness in recognition | -- |
| Hot Words | Tell the model which words may appear, separated by commas | Empty |
| Repetition Penalty | Increase this value to reduce repetitions | -- |
| Text Compression Ratio | Decrease this value to reduce repetitions | -- |
| Whisper Pre-segment Audio | Whether to pre-segment audio into sentence clips before sending to Whisper | No |
Tip: When using a clone dubbing voice, check "Whisper Pre-segment Audio" and set Min Speech Duration to 3000 and Max Speech Duration to 10. This ensures the reference audio is 3-10 seconds long, improving cloning reliability.
FAQ
Q: Subtitles are too long (tens of seconds). How do I shorten them?
- Decrease "Max Speech Duration (s)" (e.g., set to 3-4)
- Check "Merge Short Subtitles"
- Decrease "Silence Split Duration (ms)"
Q: Subtitles are too short (less than 1 second). How do I lengthen them?
- Increase "Max Speech Duration (s)" (e.g., set to 8-10)
- Increase "Min Speech Duration (ms)" (e.g., set to 3000-4000)
- Uncheck "Merge Short Subtitles"
Q: There are duplicate lines in my subtitles. What should I do?
- Increase the "Repetition Penalty" value
- Decrease the "Text Compression Ratio"
- Increase the "Sampling Temperature" (but setting it too high may cause hallucinations)
Q: How do I make the model recognize specific proper nouns?
Enter the proper nouns in the "Hot Words" field, separated by commas. For example: Beijing,Tsinghua University,ChatGPT
Related Documents
- Improving AI Translation Subtitle Quality — Translation mode comparison and glossary usage
- Using Local LLMs as a Translation Channel — Local LLM configuration guide
- Customizing AI Translation Prompts — Custom translation prompts
- Recommended Settings for Best Video Translation — Optimal configuration for each stage
- Why "Blank Subtitle Lines" Appear After Translation